운영체제 관련 글 순서
- 프로세스란
- 쓰레드
- CPU 스케줄링
- 동기화 툴
- 동시성 제어 예제
- 데드락
- 주 메모리
- 페이징과 스와핑
- 가상 메모리와 디맨드 페이징
- 페이지 교체 알고리즘(FIFO, OPT, LRU), 쓰레싱, working set
쓰레드(Thread)
- lwp(lightweight process)라고도 한다.
- 프로세스 내에서 실제로 작업을 수행하는 주체
- 모든 프로세스는 한개 이상의 스레드가 존재하여 작업을 수행
쓰레드의 자원
- 공통자원
- code
- data
- heap
- 독립적인 자원
- registers
- stack ( 지역변수, 매개변수, 리턴값)
- pc(program counter)

쓰레드는 독립적인 작업을 수행하기 때문에 각각의 스택과 PC,레지스터 값을 가지고 있다.
각각의 스택과 레지스터를 가지고 있는 이유
해당 블로그 참조: https://goodgid.github.io/What-is-Thread/
멀티 쓰레드
: 하나의 프로세스에서 다수의 실행단위(Thread)을 실행할 수 있게 해주는 것.
장점
- responsiveness
- 논블럭으로 실행 가능
- 요청이 들어오면 이후 일을 스레드에게 맡기고 요청을 계속 받고 있을 수 있음
- resource sharing
- 프로세스간의 통신시에는 shared memory 나 message queue를 써야하나, 쓰레드에선 공유 데이터가 있기에 리소스 공유에 좋다.
- economy
- 프로세스 생성하는것보다 비용적인 측면에서 좋다.
- 컨텍스트 스위칭에서도 프로세스의 생성 및 컨텍스트 스위칭보다 빠름.
- 멀티 쓰레드에서의 컨텍스트 스위칭은 데이터영역과 힙을 올리고 내릴 필요가 없음.
- 캐시메모리를 비울 필요가 없다는 뜻.
- scalability
- 확장성에서 좋다.
- 각각의 CPU 코어에 스레드를 붙여서 병렬처리 가능
단점
- 동일한 자원에 동시에 접근할 경우 문제가 생김.
- 이럴때 동기화 작업을 통해 작업 처리 순서 및 공유 리소스에 대한 접근을 컨트롤 해야함.
- 뮤텍스, 세마포어
- 불필요한 부분까지 동기화 할경우 병목현상 발생
멀티 스레드에서 컨테스트 스위칭이 일어날때
- 같은 프로세스 내 : TCB 사용(스레드의 메타데이터 저장 블록)
- 다른 프로세스의 스레드 : PCB& TCB 사용
멀티 프로세스 vs 멀티 스레드
: 멀티 프로세스는 독립적인 공간을 가지고 있어서, 하나가 문제가 발생하여도 다른 프로세스로 확산되지 않음.
멀티 스레드는 공통 자원을 사용하기때문에 하나가 장애를 일으키면 전체가 문제 생김.
하지만 멀티 스레드가 컨텍스트 스위칭에서 더 빠르고, 공유 자원을 활용하므로 효율적인 면에서 좋다.
자바에서는 스레드쓰는 방법
- 쓰레드 클래스 상속받기
- 새로운 클래스를 쓰레드 클래스를 상속받아서 실행
- 대신 다중상속이 안되기때문에 안좋음
-
class MyThread1 extends Thread { public void run() { try { while (true) { System.out.println("Hello, Thread!"); Thread.sleep(500); } } catch (InterruptedException ie) { System.out.println("I'm interrupted"); } } } -
public class ThreadExample1 { public static final void main(String[] args) { MyThread1 thread = new MyThread1(); thread.start(); System.out.println("Hello, My Child!"); } }
- runnable 인터페이스 상속하기
- 새로운 클래스가 인터페이스를 상속받고 오버라이딩하여 실행
-
class MyThread2 implements Runnable { public void run() { try { while (true) { System.out.println("Hello, Runnable!"); Thread.sleep(500); } } catch (InterruptedException ie) { System.out.println("I'm interrupted"); } } } -
public class ThreadExample2 { public static final void main(String[] args) { Thread thread = new Thread(new MyThread2()); thread.start(); System.out.println("Hello, My Runnable Child!"); } }
- lambda expression
- 새로운 클래스를 생성하지않고, 익명클래스로 실행
-
public class ThreadExample3 { public static final void main(String[] args) { Runnable task = () -> { try { while (true) { System.out.println("Hello, Lambda Runnable!"); Thread.sleep(500); } } catch (InterruptedException ie) { System.out.println("I'm interrupted"); } }; Thread thread = new Thread(task); thread.start(); System.out.println("Hello, My Lambda Child!"); } }
자바 쓰레드 명령어
- 쓰레드 시작: start()
- 자식 쓰레드 끝날때까지 대기 : join()
- 쓰레드 종료: interrupt()
멀티코어 시스템에서의 멀티 스레드
싱글 코어: time-sharing으로 실행
멀티코어: 병렬적으로 실행이 가능

멀티코어에서 고려해야할 것
- identifying tasks: 작업 처리 방법 도출
- balance: 작업량의 균형 맞추기
- data splitting: 각 코어 별 데이터 나누기
- data dependency: 동기적인 처리 동작을 위해 data 의존도를 고려
- testing and debugging: 테스트 & 디버깅의 어려움
해당 블로그 참조: https://chanto11.tistory.com/63
병렬처리 방법
- data를 쪼개서 core에 분배
- 데이터는 두고 task를 쪼개서 분배
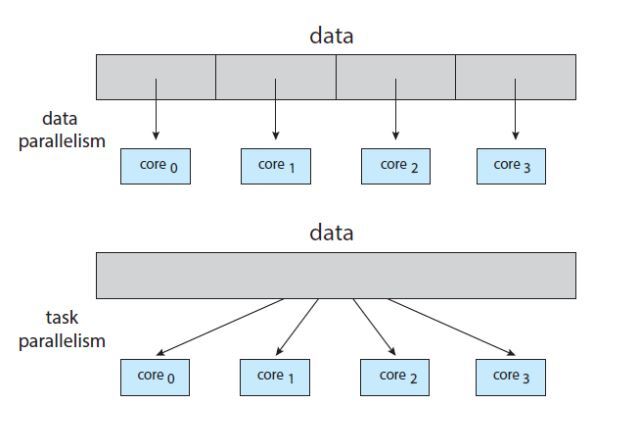
현재는 분산시스템이 가능(hadoop) 한개의 컴퓨터가 아닌 다량의 컴퓨터로 분산.
amdahl's law(암달의 법칙)
- 코어는 무조건 많을수록 좋은가?


- S: 병렬처리 가능한 부분 N: 코어의 개수
- 병렬처리가 가능한 부분에 따라 코어를 늘림으로서 얻을 수 있는 성능향상이 다름.
쓰레드의 타입
- 유저 쓰레드와 커널 쓰레드
java는 운영체제가 아니고 jvm임(virtual machine)
이 쓰레드는 운영체제가 가지고 있는 cpu를 넘나들 수 없음.(user thread)
User Thread
- 커널 위의 유저공간에서 진행(커널은 스레드로 인식 x)
- 스레드를 관리하는 라이브러리에서 생성 및 관리
- 운영체제 시스템 내에서 생성되어 동작하는 스레드
- 커널이 각 스레드를 개별적으로 관리 가능
커널 쓰레드와 유저 쓰레드의 관계
- Many to one(user-level)
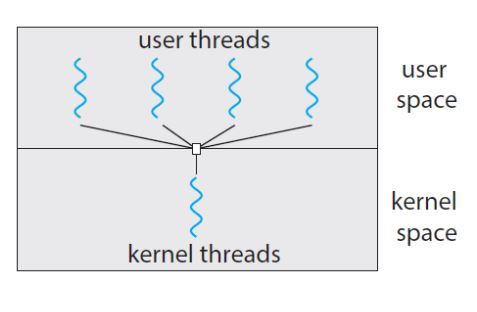
- 커널 스레드 1 : 유저 스레드 n
- 장점
- 사용자 영역에서 생성되고 관리하여 속도가 빠름
- 커널의 개입을 받지 않기때문에 이식성이 높음(모든 운영체제에서 가능)
- 단점
- 커널에선 스레드를 1개로 보기때문에 하나의 스레드가 중단되면 모든 스레드 중단
- one to one(Kernel-Level)

- 커널 스레드 1: 유저 스레드 1
- 운영체제가 지원하는 스레드 기능으로 구현
- 커널이 스레드의 생성 및 스케줄링 등을 관리
- 장점
- 커널이 각 스레드 개별 관리 -> 스레드 병행 처리 가능
- 하나의 스레드가 중단되어도 다른 스레드는 실행 가능
- 단점
- 사용자 스레드에 비해 생성 및 관리 속도 느림
- many to many(Combined)

- 커널 스레드 n : 유저 스레드 n
- 위의 두개의 스레드를 혼합하여 단점을 극복한 구조
- 장점
- 스레드 병행 처리 가능
- 스레드 풀링 기법을 통해 일대일 스레드 매핑에서의 오버헤드를 줄임
해당 블로그 참조: https://yoongrammer.tistory.com/55
쓰레드 라이브러리(유저 스레드)
- POSIX Pthreads(리눅스,유닉스에서 많이 씀)
- Windows thread
- Java thread(다양한 운영체제에서 가능)
POSIX Pthreads
-
int main(int argc, char *argv[]) { pthread_t tid; // thread identifier pthread_attr_t attr; // thread attributes pthread_attr_init(&attr); pthread_create(&tid, &attr, runner, argv[1]); pthread_join(tid, NULL); printf("sum = %d\n", sum); } void *runner(void *param) { int i, upper = atoi(param); sum = 0; for (i = 0; i <= upper; i++) sum += i; pthread_exit(0); } - runner() : 별도의 스레드는 해당 함수에서 실행
- pthread_create(): 별도의 스레드 생성
- pthread_join(): thread 종료될때까지 대기
- pthread_exit(): 스레드 종료
- 컴파일시 -pthread 걸고 해야함 ( gcc -pthread ***.c)
implicit Threading
:개발자가 스레드의 생성과 관리를 책임지지 않고 컴파일러와 라이브러리가 맡는 개념
- Thread Pools
- 풀을 만들어두고 거기서 쓰레드를 가져와서 사용
- 쓰레드를 새로 만드는게 아니라 미리 만들어둔 쓰레드를 가져와서 사용하는것!
- 다 쓴 후엔 쓰레드 풀에 반환
- 새로운 스레드를 생성해서 쓰는것보다 더 빠르게 서비스 가능
- Fork & Join
- explicit threading 을 implicit threading으로 나누는법
- 부모 스레드가 자식 스레드를 fork한 후 종료하길 기다렸다가 join하고 자식의 결과를 확인 한 후 결합하는 방법
- fork단계에서 스레드가 직접 구축되지 않고 병렬 작업만 할당하게 됨.
- pthread의 fork-join과 비슷하나, 개발자가 직접 스레드를 생성하지 않는다.
- OpenMP
- openMP는 지시어를 넣어주면 컴파일러가 멀티 스레딩을 지원
- 공유 메모리 환경에서 병렬 실행 가능하게 해줌
#include <omp.h> #include <stdio.h> int main(){ // 병렬 영역 선언 #pragma omp parallel { printf("I am a parallel region"); } return 0; }- gcc - fopenmp ***.c
- Grand Central Dispatch(GCD)
- Mac,ios 전용 apple에서 개발한 기술
참조
[주니온님의 인프런 운영체제강의(공룡책)](https://www.inflearn.com/course/%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9C-%EA%B3%B5%EB%A3%A1%EC%B1%85-%EC%A0%84%EA%B3%B5%EA%B0%95%EC%9D%98/dashboard)
'CS > OS(운영체제)' 카테고리의 다른 글
| 데드락(Deadlock) (0) | 2022.01.05 |
|---|---|
| 동시성 제어 예제(Bounded-Buffer, Readers-Writers (0) | 2022.01.05 |
| 동기화 툴(프로세스 동기화) (0) | 2022.01.05 |
| CPU 스케줄링 (0) | 2022.01.05 |
| 프로세스(Process)란 (0) | 2022.01.05 |




댓글